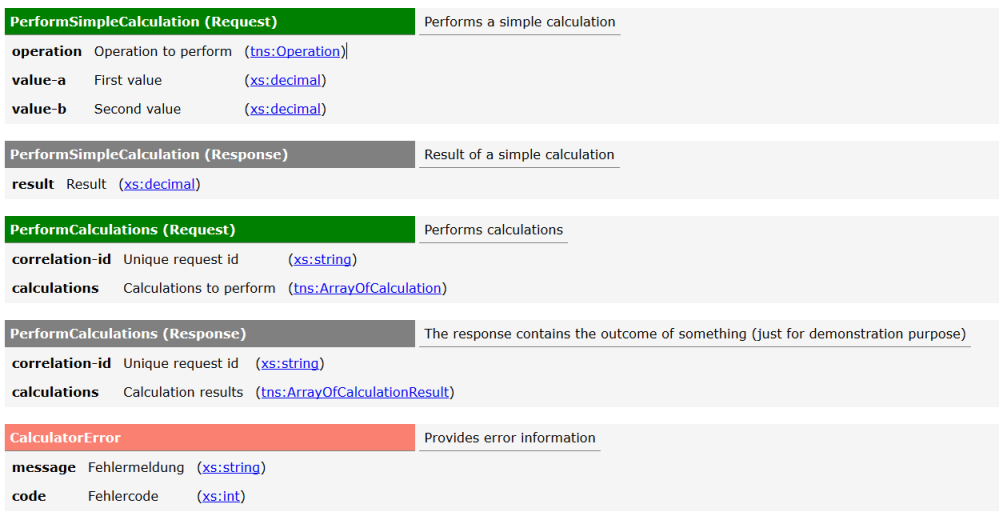
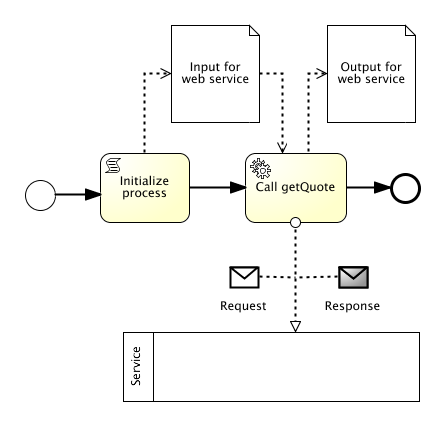
In 2016 PLEUS Consulting supported Bank11 in the development of their brand new sales financing system VICTOR 3.0.

|
Bank11 is a credit institution that specializes in sales financing. In 2016 the bank decided to replace their existing software with something new. To be able to meet the challenging requirements in terms of quality, customer satisfaction and process efficiency they decided to build their own solution.
The front-ends were developed using modern web technologies such as Javascript, HTML5, CSS and Angular. For the backend Java Enterprise (JEE) and a Sustainable Service Design approach was utilized to design and build a backend with a high degree of reuse and scalability. The service landscape was established using Domain Driven Design principles. On the technical side, PLEUS Consulting supported the teams as Master Developer and Architecture Owner. In the area of agile techniques, PLEUS Consulting supported the development teams as Scrum Master and Agile Coach. Although not 100% tension free, the combination of those roles worked quite well. With these roles the bank received thorough support in the areas of technology and methodology. From the beginning we tried to align technology and business as much as possible, creating a people centered architecture. Central to the strategy were BPMN process models, graphical business rules and visual service contracts. In order to create appealing front-ends for the car dealers and the back office of the bank we worked closely with user interface specialists which were members of the cross functional teams. Web stack technologies allowed us to create individual and great looking front-ends. Agile frameworks such as Scrum organized the development teams and created valuable software together with the customer within a short period of time. The project has shown that with a combination of modern technologies and agile approaches a very short concept to market cycle can be achieved, creating competitive advantages. It also demonstrates that it is possible to establish an agile culture in rather traditional business domains. |
You can read more details about the project in the official success story. If you want to find out more come to watch my talks at JAX 2017 in Mainz.