In my article series about Sustainable Service (SSD) design I described a design and implementation approach to develop services with technical decoupling to improve reuse.
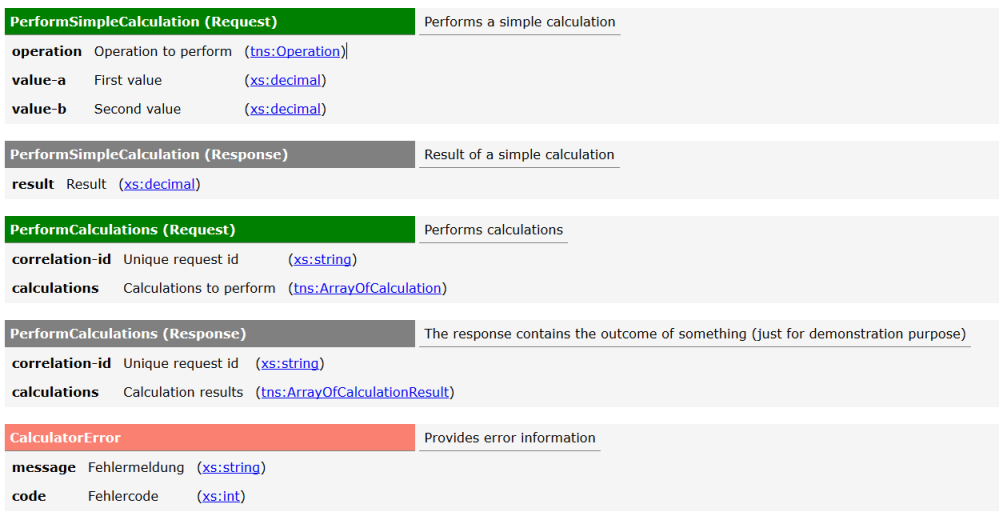
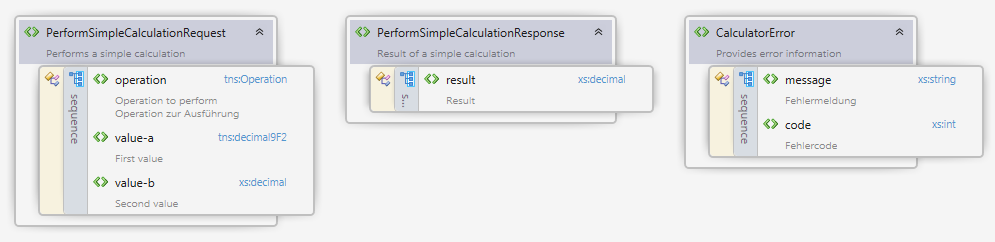
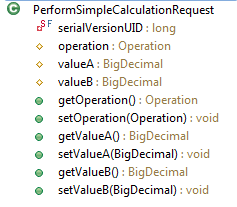
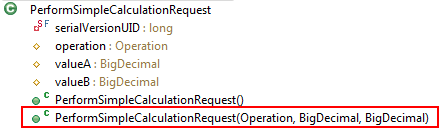
At the level of IT infrastructure sustainable means that service implementations can be used in different technical environments without a major rewrite. Technical decoupling is a key factor to achieve that. In the second part of the article I have provided an example on how to implement SSD with a JEE stack. Part of this example is a calculator service which performs simple arithmetic operations.
Due to the technical decoupling, services can be moved with little effort, for example from a JEE Server to other runtimes like Apache Karaf (OSGi) or Spring Boot, just to name a few.
In this blog post I would like to demonstrate how to move the Calculator JEE example from Wildfly JEE Container to Spring Boot. The main difference in the Spring Boot deployment is the fact that each service is bundled with its own HTTP server. The deployment unit is not a JEE EAR which is deployed on a JEE Server, but a so-called über-jar which includes the complete HTTP infrastructure. The über-jar just requires a Java runtime and no additional infrastructure. This kind of deployment creates a high level of service autonomy which is often used in Microservice architectures.
Let me tell you a little story:
Assume Peter is an IT professional who is working on a fictitious software project for a large insurance company. One day a colleague, let’s call him Max, from another project enters Peterʼs office and starts the following conversation:
Max: I’ve heard you’ve implemented some very useful services. I saw them on your service repository Wiki and think we could use some of them in our new project.
Peter: Yes, that’s right. I am glad we’ve created something valuable.
Max: But…I also heard that you are using a full blown JEE Applicationserver to run your services.
Peter: Yes, this is the best runtime for our project, as it helps us to manage centralized deployment. Each service is deployed in its own EAR file, which gives us great flexibility.
Max: For our project we decided to use Spring Boot and deploy each service together with its own HTTP Server. I guess we can’t use your service without a major rewrite then?
Peter: You don’t have to rewrite the services because we’ve implemented them based on Sustainable Service Design.
Max: Sounds great, could you please show me what we have to do to run your services?
Peter: Of course. Let’s start by downloading the Calculator Example, which demonstrates how to build SSD-Services for JEE. First, build the example like so:
mvn clean install
Peter: Now you have the following maven artifacts (jars) in your local maven repository.
net.pleus.services.calculator:calculator_api net.pleus.services.calculator:calculator_impl
Peter: You can use this artifacts without any modifications.
Max: Ok, I can see that api and impl form the core service. Our project decided to just use JSON/HTTP as the protocol for service interaction. I saw that in the orignal example REST, EJB and SOAP are provided.
Peter: No problem, just add the bindings when you need them. With SSD you can add additional bindings any time. So you can start with the bare minimum and expand later. This gives you great flexibility. Add the JSON/HTTP-binding first.
Max: In the original example I saw that it was called REST-Binding.
Peter: Although the original calculator example uses the term REST-Binding, I prefer to call it JSON/HTTP-Binding because it better describes what it is. An SSD-Service can manage multiple resources (nouns) and can support arbitrary operations (verbs). This representation is very well suited to modelling the real world (the domain) which is important for proper service design and reuse. If you really have the requirement to create REST-Style APIs, you can do it in the respective binding. But be aware that in this case you create a variation of your service contract (subcontract) which also relies on HTTP-Verbs instead of the verbs in the primary contract. Although it is possible, I would not recommend it. Ok, let’s not digress but move on with Spring Boot.
Max: Ok, please show me how to create the bootable service.
Peter: Sure, start with the following Maven-POM , which is based on the tutorial Building a RESTful Web Service with Spring Boot.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version>
</parent>
<groupId>net.pleus.services.calculator</groupId>
<artifactId>calculator_boot</artifactId>
<version>1.0-SNAPSHOT</version>
<name>Services :: calculator :: boot</name>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>net.pleus.services.calculator</groupId>
<artifactId>calculator_api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>net.pleus.services.calculator</groupId>
<artifactId>calculator_impl</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
<properties>
<java.version>1.8</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Peter: From lines 25-34 you can see the existing calculator jars. The rest is required to create a minimal Spring Boot über-jar. Now we create a JSONHTTP-Binding using Spring MVC.
@RestController
@RequestMapping(value = "/services/calculator/rest/api", method= RequestMethod.POST)
public class CalculatorJSONHTTPBinding {
@Autowired
private Calculator service;
@RequestMapping(value = "/performcalculations", method= RequestMethod.POST)
@ResponseBody
public PerformCalculationsResponse performCalculations(@RequestBody PerformCalculationsRequest request) {
return service.performCalculations(request);
}
}
Peter: To add this binding we need some boilerplate code. First an application class.
@SpringBootApplication
public class Application {
public static void main(String[] args) {
ApplicationContext ctx = SpringApplication.run(Application.class, args);
}
}
Peter: And second a little factory to create a service instance, so that it can be injected using @Autowired in the binding.
@Configuration
public class Factory{
@Bean public Calculator createCalculator(){
return new CalculatorImpl();
}
}
Peter: That’s all. Build it and run the über-jar with the following command.
mvn clean install java -jar target/calculator_boot-1.0-SNAPSHOT.jar
Max: Wow, that’s all? Can you prove that it works?
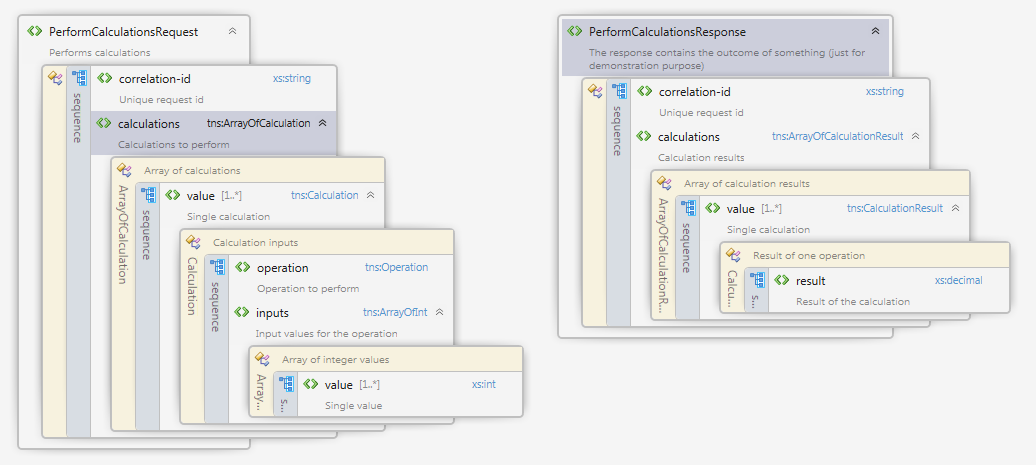
Peter: Of course. For example fire up SOAP-UI and send this request to the service at http://localhost:8080/services/calculator/rest/api/performcalculations
{
"correlationid":"4711",
"calculations": {
"value": [
{
"operation": "ADD",
"inputs": {
"value": ["1","2"]
}
}]
}
}
Peter: This is what you get.
{
"correlationid": "4711",
"calculations": {"value": [{"result": 3}]}
}
Max: Can I reuse the existing binding from the original example instead of the one we created?
Peter: Yes, but it is technically coupled to JAX-RS. If you want to use it please read the blog Using JAX-RS With Spring Boot Instead of MVC.
Max: I saw that the original example contains a handy Java client to access the service. Can I reuse it?
Peter: You mean net.pleus.services.calculator:calculator_binding_rest_client. Yes, you can use it as it is. And it makes sense, as it gives you a nice fluent Java-API to access the service. First add the following Maven artifact to your pom.xml.
net.pleus.services.calculator
calculator_binding_rest_client
1.0-SNAPSHOT
Peter: Now you can use the Java client in your tests like this.
@Before
public void setUp() throws Exception {
client = new CalculatorClient("localhost",port);
}
@Test
public void add() throws Exception {
// Create calculation inputs
Calculation calculation = new Calculation()
.withOperation(Operation.DIVIDE)
.withInputs(new ArrayOfInt()
.withValue(9,3,2)
);
// Create request
PerformCalculationsRequest request = new PerformCalculationsRequest()
.withCorrelationid(UUID.randomUUID().toString())
.withCalculations(new ArrayOfCalculation().withValue(calculation));
// Call service
PerformCalculationsResponse response = client.performCalculations(request);
// Check correlation
Assert.assertEquals(request.getCorrelationid(), response.getCorrelationid());
// Check result
Assert.assertEquals(new BigDecimal(1.5), response.getCalculations().getValue().get(0).getResult());
}
Peter: When you run the test Spring Boots starts the HTTP Server and calls the service.
Max: It seems that I can easily run your service and even use the Java client within Spring Boot. We have a sustainable service and a lightweight runtime. Perfect! That saves us a lot of time and money. Maybe we should try to evolve the service together? This way we could create further value for other projects.
Peter: Good idea! If you want to try the example I’ve packaged it for download. For convenience it also contains identical copies from the original calculator example.
Feel free to use it as you like.